Не зная ничего о природе цветов, мы могли бы наивно предположить, что каждый оттенок (красный, зеленый, синий, желтый, фиолетовый и т.д.) существует независимо от других. Однако, начав смешивать цвета, мы быстро (или не очень) придем к выводу, что действительно независимых цветов только три: красный, зеленый и синий, а все остальные являются их линейными комбинациями1 (простыми словами — смесями в различных пропорциях).
Даже у слабо знакомых с математикой товарищей не должно вызвать больших затруднений представление о цветах как о трехмерных векторах (списках из трех чисел). Но что нам дает такое представление? Во-первых, мы получаем соответствие между физическим процессом смешения цветов и арифметическими операциями над векторами. А во-вторых, это представление еще и максимально сжато, то есть занимает минимально возможное количество памяти.
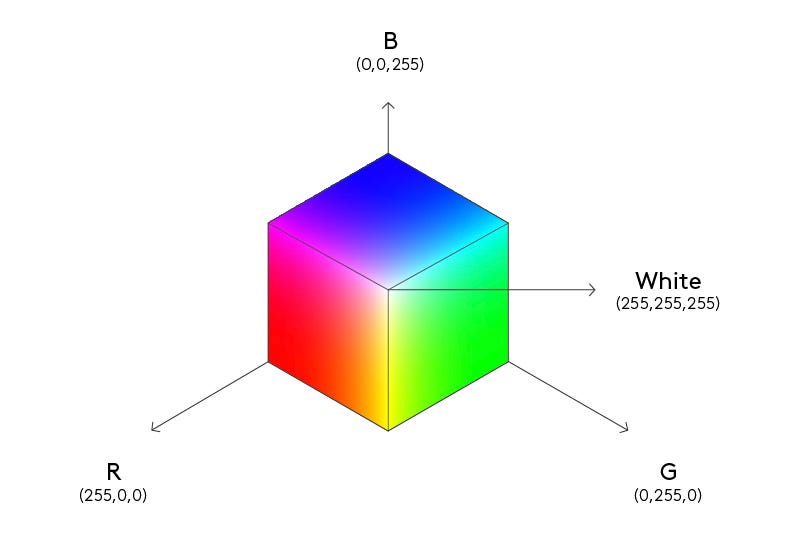
Пример с цветами хорош именно тем, что мы заранее знаем ответ. Но есть много других групп объектов, для которых мы бы хотели получить представление с аналогичными свойствами, но, как это сделать — совершенно неочевидно. Например, слова.
Опять же, мы можем начать с предположения, что все слова независимы друг от друга, то есть каждому их них в нашем пока воображаемом пространстве слов соответствует свое измерение (подобный подход называется унитарным кодированием). Но это предположение быстро разобьется о достаточно очевидные примеры антонимов, вроде «высокий — низкий», «яркий — тусклый», «помогать — мешать», «громко — тихо». Для каждой пары антонимов мы можем записать пока условное уравнение вида «высокий + низкий = 0», «помогать + мешать = 0» и т.д. Таким образом мы алгебраически выражаем одно слово через другое, а значит, можем избавиться от одного из двух измерений, которые изначально на них выделили. Более того, в правой части этих уравнений не обязан стоять ноль: там может быть и ненулевой вектор, то есть другое слово. Например: «сыро + холодно = промозгло», «ирония + насмешка = сарказм», «музыка + стихи = песня». Поднимаясь на уровень выше, до четырех слов в одном уравнении, мы можем начать иллюстрировать различные виды взаимосвязи между словами. Например, «король - мужчина + женщина = королева» — семантическая (смысловая) взаимосвязь, а «большой + меньше = маленький + больше» — синтаксическая. И это лишь самые простые примеры; нет предела сложности для подобных построений.
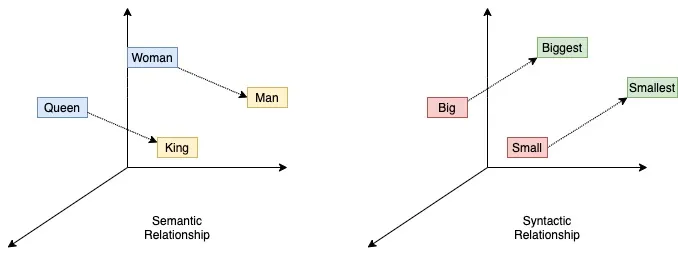
Проблема в том, что рассматривать все возможные словесные уравнения для выражения слов друг через друга и определения взаиморасположения соответствующих им векторов — задача, по трудоемкости далеко выходящая за рамки разумного. Поэтому решена она была лишь с появлением машинного обучения. Прорывом в векторизации слов был незамысловато названный алгоритм word2vec, опубликованный десятилетие назад. Широкой публике он запомнился такими мемными примерами словесных уравнений:
pig - oink + Santa = HO HO HO
pig - oink + Woody Woodpecker = Yabba dabba doo
pig - oink + Fred Flinstone = wassup
pig - oink + Homer Simpson = D’oh
pig - oink + Donald Trump = YOU’RE FIRED
pig - oink + Einstein = E = mc2
Вместе с машинным обучением появилось и новое слово для описания подобных векторных представлений объектов — эмбеддинги. Противники англицизмов могут также использовать словосочетание «латентный вектор», т.к. пространство, в котором располагается эмбеддинги, называется латентным. Но я здесь и далее буду использовать общепринятую в отрасли терминологию.
Алгоритм генерации эмбеддингов оказался довольно неочевидным. Состоит он в обучении модели — как правило нейронной сети — угадыванию информации. Например, в случае со словами, мы можем изъять одно слово из предложения и заставить модель угадать, что должно стоять на его месте. Эмбеддинги при этом генерируются в процессе обучения как внутренние представления модели о данных, с которыми она работает. Если после этого объяснения ничего не стало понятно, то важно запомнить лишь одну вещь: связь эмбеддингов с предсказаниями. Вскоре эта связь нам понадобится.
Кстати, интересное свойство языка состоит в том, что эмбеддинги слов из разных языков будут образовывать очень похожую структуру, и, накладывая друг на друга латентные пространства различных языков, можно создавать словарь для перевода между ними, при этом не имея ни единого примера самого перевода. Само это свойство было известно уже очень давно, хоть и в иной формулировке, и использовалось археологами для расшифровки мертвых языков, задолго до машинного обучения. Оно указывает на то, что эмбеддинги не произвольны, а являются объективным свойством (а точнее — гомоморфным образом) того, что кодируют — то есть, в пределе разные методы вычисления эмбеддингов должны приводить к схожим результатам.
![]()
При помощи машинного обучения можно вычислить эмбеддинги для чего угодно, при условии, что у нас есть достаточное число примеров, иллюстрирующих взаимосвязи интересующих нас объектов. Например, тексты можно использовать для построения эмбеддингов слов; но можно брать и более высокоуровневые структуры — предложения, абзацы, целые статьи: они просто потребуют гораздо больше примеров. С изображениями немного сложнее, но если вы когда-нибудь решали капчу вида «выберите все квадраты, в которых содержится X, чтобы доказать, что вы не робот» — вы помогали какой-то корпорации (скорее всего Google) создавать более качественные эмбеддинги изображений.
Готовые эмбеддинги можно использовать, например, для поиска похожих объектов. Именно так работает поиск по картинкам, распознавание лиц и рекомендательные алгоритмы. И даже большинство текстовых поисковиков уже используют эмбеддинги, чтобы искать не только буквальные совпадения с поисковым запросом, но и похожие по смыслу тексты, написанные другими словами — такой поиск называется семантическим.
Еще технология эмбеддингов стала одним из столпов почти всех прорывов в области искусственного интеллекта за последние годы, что неудивительно: они, по сути, представляют собой портал между реальным миром, с которым работают люди, и цифровым миром, с которым работают компьютеры. На них опирается и ChatGPT, и другие генеративные нейросети вроде Stable diffusion и Midjourney.
Чуть ранее вы могли задаться справедливым вопросом: а как определять необходимую размерность латентного пространства? В примере с цветами мы знали ответ заранее, но вот со словами все уже не так однозначно. Ответ, на первый взгляд, удручающий: в общем случае мы не знаем, какую размерность использовать, и просто выбираем ее методом научного тыка. Но хорошие новости в том, что эту проблему можно обойти. Для этого нужно всего лишь отсортировать измерения латентного пространства в порядке убывания важности свойств, которые они кодируют. Рассмотрим в качестве примера задачу распознавания лиц: мы не знаем, сколько независимых свойств существуют у человеческих лиц. Но мы можем сказать, например, что одно из важнейших свойств — пол, так так лица мужчин и женщин обычно существенно различаются (заранее приношу извинения транс-персонам). Тогда, поставив пол в начало эмбеддинга, мы сильно упрощаем себе задачу сравнения двух лиц, так как почти в половине случаев можем дать отрицательный результат сравнения уже по первому биту. Теперь нам уже не так важно, сколько элементов остается в «хвосте» вектора, поскольку в большинстве случаев мы просто не будем их использовать. Я бы назвал такой подход «ленивым эмбеддингом», но это не общепринятое название.
Но что представляют собой эмбеддинги на фундаментальном уровне? Согласно формальному определению, это всего лишь вектора, геометрическое расстояние между которыми пропорционально схожести объектов, которые они представляют (изометрический гомоморфизм, если угодно). По сути, вычисление эмбеддингов — это задача классификации объектов, определения степени их родства, что бы это ни значило в каждом конкретном случае.
Но, как я мельком упомянул в начале, побочным эффектом вычисления эмбеддингов оказывается сжатие информации2. И уже есть основания предполагать, что в действительности это не просто побочный эффект, а эквивалентное определение эмбеддинга. Это основание — безумно интересная статья, в которой эмбеддинги текстов, полученные при помощи мощнейших языковых моделей, сравниваются с результатами сжатия тех же текстов обычным архиватором Gzip. Ключевая идея авторов состояла в нахождении способа измерения расстояния между текстами при помощи сжатия, тем самым позволяя использовать сжатые тексты в качестве квази-эмбеддингов в задаче классификации. И, парадоксальным образом, во многих тестах (особенно на маленьких выборках и вне обучающего распределения) производительность Gzip вплотную подобралась к гораздо более сложным языковым моделям.
Если вы сейчас ничего не поняли, то вот вывод более простыми словами. Задача классификации объектов с необходимостью требует выделения у них общих свойств; но если мы нашли такие свойства, то нам больше не нужно запоминать их для каждого объекта в отдельности — достаточно сделать это один раз для всех объектов одного класса. И напротив — задача сжатия информации требует сокращения повторяющихся последовательностей, которые как раз и оказываются общими свойствами объектов. Иными словами, обе задачи сводятся к обобщению.
А теперь обратите внимание на то, что в предыдущем абзаце никак не фигурируют ни машинное обучение, ни даже сами эмбеддинги. Это куда более общий принцип, применимый, в том числе, к человеческому мозгу. Доказательствами этому могут послужить результаты исследований в области декодирования мыслей: только в этом году в ней было получено два совершенно фантастических результата.
Первый — семантическая реконструкция языка, то есть декодирование слышимой, читаемой и даже воображаемой (внутренней) речи. Причем разработанная система воспроизводит слова не точь-в-точь, а в немного иной формулировке, сохраняющей общий смысл — отсюда и квалификатор «семантическая». Это означает, что она реконструирует именно сами мысли, а не, например, моторные сигналы, которые мозг непроизвольно отправляет языку и гортани, даже когда не говорит вслух. Но самое интересное, что если использовать ту же систему на человеке, который смотрит немой фильм, то результатом декодирования его мыслей будет текстовое описание сцен этого фильма!
Второй результат — аналогичная система, но уже для реконструкции изображений, видимых или воображаемых. Свойства у нее те же: изображения не совпадают точь-в-точь, но похожи довольно любопытным образом, отражающим детали, на которые человек обращает внимание.
Обе системы построены практически идентичным образом и содержат два ключевых элемента:
- Генеративная нейросеть. Семантическая реконструкция языка использует GPT-1, а реконструкция изображений — диффузионную модель из того же класса, к которым принадлежат Stable diffusion и Midjourney.
- Модель мозга испытуемого, то есть нейросеть, которая по данным (тексту или картинке) предсказывает, какие сигналы будет производить мозг, думающий об этих данных. Меня поразил сам факт того, что это возможно — по идее, моделирование человеческого мозга не должно быть достижимо при существующем уровне технологий. Тем не менее, оно есть и оно работает. Даже если на данный момент это всего лишь грубая аппроксимация, сам факт того, что подобная аппроксимация возможна, сильно меняет представление о сложности этой задачи. К счастью, для получения результата модель нужно индивидуально обучать на каждом испытуемом, что невозможно без его сотрудничества; так что о принятии чтения мыслей на вооружение государствами и корпорациями беспокоиться пока рано. Пока.
Работает такая система следующим образом. Сначала генеративная нейросеть создает множество различных вариантов текста или изображений. Эти варианты подаются на вход нейросети, моделирующей мозг, и она генерирует соответствующие им сигналы. Они сопоставляются с реальными сканами мозга испытуемого и выбирается наиболее подходящий. Породившие этот сигнал данные поступают на выход системы как декодированный результат, но в то же время передаются обратно в генеративную модель, которая генерирует подходящее для них продолжение.
Все это поразительным образом напоминает описанный выше механизм семантического поиска, то есть сопоставления данных по их эмбеддингам, где аналогом эмбеддинга выступают сигналы мозга. И действительно, более ранние исследования независимо подтверждают, что мозги тоже используют концепцию латентного пространства, а процесс консолидации памяти в гиппокампе поразительно напоминает вычисление эмбеддингов. Особенно поражает статья, показывающая эквивалентность между моделью гиппокампа и трансформерами — классом искусственных нейросетей, которые лежат в основе недавних прорывов в обработке естественного языка (в т.ч. GPT) и которые разрабатывались без всякой оглядки на нейробиологию. В общем, люди в очередной раз пришли к решению, которое уже было придумано природой3. Но тут впору задаться вопросом: а какую задачу решала природа?
С одной стороны, адаптивную ценность человеческого мозга невозможно переоценить (сказал человеческий мозг, да-да), а значит, его развитие должно было очень сильно поощряться отбором; в пользу этого говорит его относительно быстрая эволюция. С другой стороны, биофизика накладывает на параметры мозга достаточно жесткие ограничения, в которые он вплотную упирается. Это, во-первых, габариты, ограниченные возможностью человека физически родиться. Во-вторых, мозг человека уже потребляет пятую часть всей энергии организма, а энергия в природе — жестко ограниченный ресурс, и возможности свободно увеличивать ее потребление (до совсем недавнего по эволюционным меркам возникновения сельского хозяйства) не было. Таким образом, мы имеем очень острое противоречие между необходимостью наращивать мощность мозга для повышения его адаптивной ценности и ограничениями на параметры, за счет которых это можно было бы сделать. Из этого следует, что эволюция мозга должна была идти в направлении повышения эффективности. И действительно, похоже на то, что его эффективность уже упирается в физические пределы. На это намекают и многие другие адаптации человека, направленные на повышение энергоэффективности ценой потери грубой силы.
Но за счет чего эта эффективность достигается? За ответом снова придется обратиться к машинному обучению, в котором было установлено, что если ограничить модель в энергетическом бюджете, она автоматически вырабатывает механизм предиктивного кодирования — тот самый, который используется для вычисления эмбеддингов! Причем перенос этого результата с искусственных нейросетей на биологические не является прыжком веры: нам уже достоверно известно, что механизмы предиктивного кодирования возникают практически в любой хорошо оптимизированной части мозга.
Поскольку человек проводит большую часть времени в общении с другими людьми (или, по крайней мере, проводил, пока не изобрел интернет, будь он неладен), оптимизация социального взаимодействия была у эволюции в высоком приоритете. Результатом этой оптимизации стал, с одной стороны, высокоспециализированный языковой центр мозга, который постоянно пытается предсказать, что услышит или прочитает; а с другой — зеркальные нейроны, которые целиком моделируют психическое состояние других людей (а при должном развитии — не только людей), и потому неизбежно оперируют со сжатыми представлениями, ибо ни одна система не может полностью моделировать саму себя.
Работу всех этих систем можно обнаружить самому, если присмотреться к нюансам собственного поведения в процессе взаимодействия с любой информацией. Например, открывая статью, я полубессознательно отмечу ее автора; и, если я уже читал предыдущие статьи того же автора, то мой мозг быстро сгенерирует представление о том, что я сейчас буду читать. Это, с одной стороны, упрощает процесс чтения и экономит энергию; но, с другой, стремление к такой экономии легко приводит людей в эхо-камеры.
Кстати, отдел мозга, формирующий такие предсказания, сильно напоминает генерирующие текст нейросети вроде GPT — пусть даже чисто функционально. Мы точно знаем, что генерацией речи и ее анализом в мозге занимаются разные отделы: зона Брока и зона Вернике соответственно. Это разделение отражено, например, в знаменитом совете Хемингуэя «Пиши пьяным, редактируй трезвым». И оно же позволяет предположить, чем ограничены сегодняшние языковые модели и как преодолеть это ограничение. Вместо того, чтобы создавать одну модель, способную одновременно «писать и редактировать», нам нужно сделать что-то более похожее на мозг: создать отдельную модель «редактора», а потом соединить ее с генеративными моделями.
«Чего не могу воссоздать, того не понимаю» — говорил Ричард Фейнман. Если мыслить таким образом, то сложно не прийти к выводу, что создание искусственного интеллекта — наша самая успешная попытка понять интеллект свой собственный.
С теоретической точки зрения все это прекрасно укладывается в общую канву теорем, сформулированных для любых систем, включая мозги, в рамках кибернетики. Одна из таких теорем утверждает, что если рассматривать субъекта и мир, с которым он взаимодействует, как обменивающиеся информацией компьютеры, то принятие оптимальных решений для субъекта — что эквивалентно предсказанию последствий тех или иных действий — необходимо сводится к максимальному сжатию информации о мире. Конечно, переносить эту теорему на реальный мир было бы преждевременно, поскольку строится она на довольно лихом допущении. Но и игнорировать ее вывод было бы в равной степени неразумно.
А теперь следите за руками: пришло время соединить все воедино. Экономия порождает предсказание, предсказание порождает обобщение, обобщение эквивалентно сжатию… А что есть сжатие? Это экономия!4 Круг замкнулся, а это значит, что все эти процессы на фундаментальном уровне эквивалентны друг другу!
После получения этого вывода мне сразу вспомнилась лемма, которую я доказывал в статье про Черный аттрактор. Тогда мне надо было найти универсальное определение интеллекта; но вместо этого я нашел три и попробовал доказать, что в пределе они эквивалентны. Теперь же этот результат можно значительно обобщить, выразив эти определения через категории, эквивалентность которых установлена абзацем выше. Первое определение я взял из книги «Что такое жизнь с точки зрения физики» Эрвина Шрёдингера, второе — из «Уравнения разума» Александра Висснера-Гросса, а третье — из «Принципа свободной энергии» Карла Фристона:
- Определение Шрёдингера: «Система считается живой, если она может уменьшать свою внутреннюю энтропию или поддерживать ее на постоянном уровне за счет увеличения энтропии окружающей среды». Оно использует понятие энтропии, которое существует одновременно в термодинамике и теории информации, причем в последней она характеризует степень сжимаемости — то есть, максимально сжатая информация обладает максимальной энтропией.
- Определение Висснера-Гросса: «Система считается разумной, если ее действия направлены на максимизацию свободы ее действий в будущем». Это определение неявным образом требует от разумной системы способности к предсказанию, потому что иначе рассуждения о будущем просто не имеют смысла.
- Определение Фристона: «Живая система стремится минимизировать дисперсию своих ощущаемых состояний, используя эти ощущения для определения состояния окружающей среды». На первый взгляд это самое непонятное из трех определений, но на самом деле его проще всего подвести под нужные нам категории: по сути Фристон описывает обобщенный вариант уже знакомого нам механизма предиктивного кодирования.
Это пока не тянет на доказательство, но указывает на возможную эквивалентность данных определений не только в пределе, но и вообще. А еще это напомнило мне о том, как интеллект определяется в марксистской гносеологии — через принцип отражения. Он описывает процесс познания посредством двух взаимосвязанных требований и соответствующих им процессов: активного извлечения нужных и исключения ненужных сведений об объекте исследования. Однако, в рамках марксистской гносеологии никогда не был дан ответ на вопрос о том, как определять нужность и ненужность сведений a priori — до того, как появляется возможность оценить их полезность в непосредственной практике. Но давайте зададимся вопросом: как именно мы используем знания в практике? Самый общий ответ на него — для осуществления предсказаний: чтобы понимать потенциальные результаты действия до его фактического совершения. А из выведенного чуть выше соотношения мы знаем, что предсказание требует сжатой модели анализируемого объекта. Следовательно, априорную нужность сведений можно определить по их экономности; а потому отражение можно записать в одну группу эквивалентности с предсказанием, сжатием и обобщением.
Иронично, что перу Ленина, который в основном и разработал марксистскую гносеологию, также принадлежит критика экономности как критерия истины в книге «Материализм и эмпириокритицизм». Критиковал он философию Эрнста Маха, исходной предпосылкой которой как раз был принцип экономии мышления — требование максимально простого объяснения наблюдаемых фактов в науке (которое Мах также выводил из биологической необходимости); по сути, это усиленная версия Бритвы Оккама. Вдвойне иронично, что большинство людей, знакомых с философией эмпириокритицизма, знают ее именно по Ленинской интерпретации из этой книги. Причем критика Ленина была вполне оправдана: сам Мах доигрался с принципом экономии мышления до отрицания причинности и материальности мира вообще. Вот как это произошло.
Если мы принимаем, что (1) экономность является достаточным критерием истины и (2) мозг всегда стремится к экономии мышления, то из этого следует, что все люди по мере накопления опыта должны сходиться к идентичным представлениям о мире. Но эмпирически этого очевидно не происходит. Объяснить это несоответствие можно двумя способами. Способ, который выбрал Мах — отрицание материальности мира. Действительно, если каждый наблюдатель созерцает свой собственный мир, то и согласованности между их моделями этого мира взяться неоткуда. Вот только есть куда более экономный способ объяснить то же противоречие: отказаться от одного из постулатов Маха. Поскольку выше я уже рассказывал, что постулат 2 по сути подтвердился наукой, то проблема, очевидно, в постулате 1. То есть, экономность является не достаточным, а необходимым критерием истины. Простыми словами это означает, что нельзя найти истину, следуя за одной лишь экономностью (теория струн и суперсимметрия нам это прекрасно продемонстрировали), но истина почему-то всегда оказывается экономной.
А как можно количественно характеризовать экономность теории? Ричард Докинз предложил использовать для этого отношение количества явлений, которая теория объясняет, к количеству недоказуемых в рамках самой теории утверждений, на которые она опирается. Эту величину также называют объяснительной силой, потому что объяснение в контексте науки5 — не что иное, как описание явлений при помощи минимального количества сущностей. Например, для теории эволюции в числителе этой дроби стоят миллионы видов живых существ, а в знаменателе — лишь существование генов, что делает ее одной из самых экономных теорий в истории науки.
Более формальную метрику экономности предложил Рэй Соломонов, опираясь на применение Колмогоровской сложности к цифровому представлению теорий. Я не буду углубляться в его наработки в этой статье, поскольку они не предлагает ничего нового в плоскости гносеологии, а лишь надстраивают математический формализм над парадигмой экономии мышления. Но польза от этого формализма, безусловно, есть — на базе него уже пытаются разрабатывать альтернативные модели сильного ИИ.
Несложно заметить, что научный прогресс почти всегда идет в направлении более экономных теорий — по крайней мере, если рассматривать его в достаточно крупном временном масштабе. Например, когда была впервые описана радиоактивность, она вообще никак не вписывалось в существующие физические теории, и первоначально ее пришлось рассматривать как совершенно независимую сущность, что в краткосрочной перспективе, конечно, не экономно. Но в скором времени появились новые теории, объединяющие старую физику с новыми явлениями в единую и более экономную систему, и заодно объясняющие вещи, прежде казавшиеся необъяснимыми — например, почему горят звезды и откуда взялись атомы. Почти наверняка на эту закономерность опирался и Мах, разрабатывая свою философию.
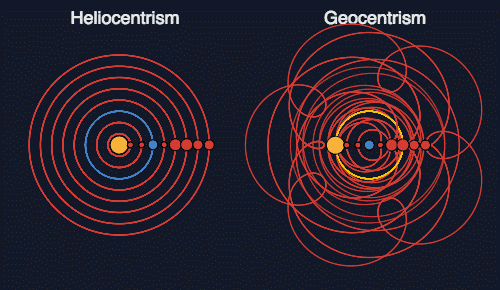
Но бывают и ситуации, где принцип экономии мышления все-таки можно использовать в качестве критерия истины, а именно — при прочих равных. Например, если мы поставим себя на место людей, которые еще не знают о теории всемирного тяготения Ньютона, то как мы должны выбрать между геоцентрической и гелиоцентрической космологическими моделями? Обе они дают достаточно точные предсказания, так что отбросить одну из них экспериментально не получится. А в чем их различие? В том, что гелиоцентрическая модель использует фиксированное и небольшое число параметров для описания орбит, тогда как геоцентрической для достижения той же точности требуется накручивать эпициклы на эпициклы, порождая тем самым в разы больше параметров. Позже Жозеф Фурье изобретет один из мощнейших инструментов математики — одноименное преобразование, которое позволяет подобным образом описать вообще любую траекторию или сигнал. То есть геоцентрическая модель плоха не потому, что неверна, а потому, что не содержит в самой себе информации о движении планет — вся эта информация находится в ее калибровочных параметрах. Гелиоцентрическая же модель сжимает эту информацию, экономя параметры — и это делает ее предпочтительной. Иными словами, гелиоцентрическая модель имеет большую объяснительную силу.
Особняком в этом отношении стоят статистика и машинное обучение. Они, как правило, используют именно «Птолемеевское моделирование» — то есть, большинство статистических моделей содержат информацию о моделируемой системе именно в калибровочных параметрах, а не в самой своей структуре. Это вынужденный подход, к которому мы прибегаем, когда разработать «Коперниканскую» модель для исследуемой системы аналитически слишком сложно. Расплатой за использование такого подхода обычно оказывается неспособность модели к обобщению. И для того, чтобы хотя бы частично ее вернуть, были придуманы методы регуляризации и снижения размерности. Заключаются они в том, чтобы искусственно ограничить сложность модели по количеству или по значениям параметров — по сути, заставить модель быть более экономной. Несложно заметить, что эти методы опасно близко подходят к использованию экономности как достаточного критерия истины; но практика показывает, что они работают, и именно практика есть окончательный критерий истины.
Но не следует отождествлять простоту теории в бытовом понимании и ее экономность — они как раз могут не совпадать. Например, никто не считает простой теорию относительности (которая, кстати, была отчасти вдохновлена философией Маха), но по сравнению с классической механикой она намного более экономна, поскольку использует для описания тех же явлений меньшее количество независимых сущностей. Не следует также путать экономность самой теории и экономность ее предсказаний. Например, та же эволюция предполагает постепенное накопление изменений на протяжении миллионов поколений и абсолютно бессмысленное рождение квадриллионов организмов, которые сразу же умрут из-за случайной мутации, делающей их нежизнеспособными. Выглядит этот процесс крайне не экономно, особенно по сравнению с идеей разумного замысла. Экономно только его объяснение. А сама природа вовсе не обязана быть экономной.
Но вернемся к противоречию в философии Маха. Даже отбросив принцип экономии мышления как достаточный критерий истины, мы все равно остаемся с вопросом: почему разные люди приходят к совершенно разным представлениям о мире, если его экономное (сжатое) представление, которое стремится найти мозг, должно быть объективным и не зависеть от наблюдателя? Ответить на него поможет другое направление философии — диалектика.
Из диалектики нам сегодня потребуется понятие «Aufhebung», условно переводимое как «преодоление» или «снятие». На русском оно используется в конструкции вида «X преодолевает Y, сохраняя его в снятом виде». Проиллюстрировать значение этой фразы проще всего на хрестоматийном примере общей теории относительности и квантовой механики, которые преодолевают классическую механику, сохраняя ее в виде частного случая при предельном переходе скорости света к бесконечности и постоянной Планка к нулю соответственно. При этом технически можно сказать, что эти теории противоречивы, потому что эмпирически скорость света не равна бесконечности, а постоянная Планка не равна нулю. Но важно то, что более развитые теории могут с легкостью моделировать менее развитую путем подобных мысленных экспериментов.
Процедура диалектического преодоления неоценима в теоретических спорах, где оппонент непременно будет приводить факты, которые не вписываются в вашу теорию. Если вы не можете использовать процедуру диалектического преодоления, то окажетесь зажаты между двумя заведомо проигрышными вариантами: оспариванием фактов и выносом фактов из области применимости теории. А вот умение преодолевать подобные противоречия не только позволяет не проиграть спор, но и превращает дискуссию в полноценную исследовательскую деятельность, потенциально способную привести к новым открытиям. В таком споре действительно может рождаться истина. Надеюсь, вы уже заметили, что ровно это я проделал выше со спором Ленина и Маха.
Однако, проще всего проследить процесс диалектического преодоления не на дискуссиях между разными людьми, а в процессе развития одного человека — себя. У каждого из нас в глубине шкафов или жестких дисков найдется какое-нибудь творчество из древних времен, посмотрев на которое, можно умереть от кринжа понять, каким образом развивалось наше мировоззрение. И основной закон этого развития — сохранение преодоленных этапов в снятом виде. Мы никогда не выбрасываем весь предыдущий опыт, чтобы начать с нуля. Даже радикально меняя свое мировоззрение, в новом мы сохраняем отпечаток старого, который усиливает его: например, позволяет гораздо более компетентно отстаивать новое мировоззрение по сравнению с неофитами, которые пришли к нему с чистого листа.
И в этом состоит огромное преимущество диалектического метода: в нем ничего не пропадает зря. Для диалектика нет человека, который бы ничему не мог его научить. «Каждая соринка — тоже витаминка», когда дело касается информации; и это положение оспаривает более конвенциональное представление в социальной психологии, согласно которому существуют «опасные идеи», от которых людей надо ограждать. В этом смысле метод экономии мышления действует тождественно критическому мышлению. В полноценной диалектической модели реальности можно найти место для любого эмпирического факта и отпечаток любой теории, объясняющей хотя бы какие-то из этих фактов. И это значит, что с помощью диалектики можно — хотя бы в пределе — синтезировать такую теорию, с которой смогут согласиться все.
По тем же причинам ни одну общепринятую теорию в современной позитивной науке нельзя опровергнуть. Единственный способ продвинуться дальше в познании — преодолеть старую теорию, то есть найти более общую теорию, частным случаем которой будет являться старая — или, в диалектической терминологии, которая сохраняет старую теорию в снятом виде. Но поскольку обобщение, как мы выяснили выше, эквивалентно сжатию, то получается, что результат диалектического преодоления должен быть более экономным. А поскольку диалектическое преодоление — процесс снятия противоречий, то можно сформулировать и обратное суждение: чем более экономны наши теории, тем меньше между ними противоречий.
Но есть у этой архитектуры и существенный недостаток: монолитность, то есть невозможность перенести часть знаний из одной модели в другую. Возвращаясь к примеру эмбеддингов, мы можем наблюдать проявление этой проблемы в том, что сами эмбеддинги бесполезны без модели, которая их сгенерировала. Причем невозможно провести обратное преобразование — воссоздать модель на основе ее эмбеддингов. По той же самой причине невозможно просто «скачать» накопленные человечеством знания в мозг отдельного человека. Каждый мозг — это новая модель, и каждый должен самостоятельно выстраивать свое «латентное пространство» с нуля, а для этого он должен концептуально пройти весь путь, который уже прошли его предшественники (это косвенно подтверждается приведенными выше исследованиями по чтению мыслей, где под каждого испытуемого нужно обучать свою модель). Развитие личности в миниатюре повторяет развитие всей цивилизации, в которой ей довелось родиться. Это, кстати, накладывает на наши возможности познания неприятное ограничение: рано или поздно время, необходимое для повторения пути человечества даже в самом миниатюрном виде, превысит продолжительность жизни, и у новых поколений просто не будет достаточно времени, чтобы создать что-то оригинальное; следовательно, искусственное продление жизни или иные способы выхода за это ограничение (например, коллективный разум) станут необходимым условием дальнейшего прогресса. Но сегодня не об этом.
Та же логика объясняет, почему переубеждение людей в общем случае не работает. Невозможно подобрать такой «эмбеддинг», который сможет сходу встроиться в «латентное пространство» другого человека, не имея доступа к его субъективному опыту (который нам недоступен по определению). Только я сам могу в чем-то переубедить себя — либо для того, чтобы разрешить противоречие в имеющемся представлении о реальности, либо под действием материальных факторов. На первом варианте основана «майевтика» Сократа: она заключается в том, чтобы определить противоречия в мировоззрении собеседника и сделать их максимально очевидными для него. Иногда это приводит к тому, что собеседник проводит рефлексию и меняет свое мнение, чтобы снять противоречие. Но гарантировать переубеждение, тем более в пользу конкретной позиции, невозможно. Сократу это и не требовалось: в его теории познания каждый человек уже априорно содержал в себе истинные знания о мире, и их требовалось лишь правильно извлечь. Но это вовсе не значит, что методология Сократа бесполезна для нас, материалистов.
И вот, наконец, я готов представить то, ради чего был написан этот текст: метод диалектической дискуссии.
Первое правило диалектической дискуссии: нужно вообще отказаться от идеи, что оппонент может быть абсолютно неправ. Такие ситуации — скорее исключение. В терминах диалектического материализма, «всякий является носителем относительной истины». В общем случае каждый человек вырабатывает такую модель реальности, которая объясняет его субъективный опыт; а этот опыт, в свою очередь, представляет собой лишь очень ограниченный срез объективной реальности. Такие ограниченные модели вполне могут быть внутренне непротиворечивыми, но взаимоисключающими. В такой ситуации все существующие методы дискуссии оказываются бесполезны: ни один оппонент не может подловить другого на противоречии, но в то же время не может и найти общности, на которой можно было бы строить какой-то компромисс.
И здесь нам поможет выведенное ранее суждение: «чем более экономны наши теории, тем меньше между ними противоречий». В терминах моделей и диалектики его можно переформулировать следующим образом: размерность модели, преодолевающей противоречие и сохраняющей его в снятом виде, меньше суммы размерностей противоречивших моделей. А о размерности мы в последний раз говорили в контексте ее снижения и регуляризации. И это наталкивает нас на второе правило диалектической дискуссии: регуляризацию тезисов. По аналогии с машинным обучением, у нас есть два взаимодополняющих пути ее проведения:
- Первый, аналогичный снижению размерности — это удаление избыточных понятий. Прежде, чем переходить к логическому анализу тезисов, следует в пределах разумного минимизировать количество понятий, которые используются в тезисах обоих участников дискуссии, путем выражения одних понятий через другие. Это также поможет убедиться, что участники одинаково понимают используемые понятия. Высшим пилотажем будет введение новых терминов, обобщающих старые и позволяющих взглянуть на вопрос в такой проекции, где разрешение исходного противоречия становится самоочевидным.
- Второй, аналогичный регуляризации, примерно совпадает с правилом Сагана «экстраординарные утверждения требуют экстраординарных доказательств».
И, наконец, третье правило диалектической дискуссии, неразрывно связанное со вторым, можно сформулировать так: «на каждом этапе дискуссии должна сохраняться возможность для внешнего наблюдателя вступить в нее, не требующая изучения всех предшествующих материалов». На первый взгляд это правило может звучать произвольно, но на самом деле оно представляет собой не что иное, как адаптацию популярной максимы о дискуссиях в рамках позитивных наук:
Если вы учёный, квантовый физик, и не можете в двух словах объяснить пятилетнему ребёнку, чем вы занимаетесь, — вы шарлатан.
— Ричард Фейнман
Ту же мысль многократно формулировали другие ученые в различных вариациях, например, с уборщицей вместо ребенка. Я не упущу возможность в очередной раз порекомендовать очерк Фейнмана, раскрывающий эту тему более подробно, и всю книгу, из которой он взят. Происходит эта максима из наблюдения, что дискуссии в «замкнутом пространстве» склонны накапливать скрытую сложность, которую не осознают сами дискутирующие, но которая мешает им приходить к верным ответам. Бороться с этим можно разными путями. Высший пилотаж — когда сами участники дискуссии держат у себя в головах модели того «пятилетнего ребенка» и постоянно объясняют свои тезисы этой модели; своего рода продвинутая самокритика. Понятно, что рассчитывать на это в общем случае не приходится, поэтому критика должна исходить извне. Можно действительно привлекать новых людей в дискуссию на каждом ее витке и заставлять дискутирующих вводить их в курс дела. Или можно заставлять их писать сводки/дайджесты по ходу дискуссии и публиковать их в открытый доступ. Любое из этих решений при правильной реализации будет удовлетворять третьему правилу, а придумывание новых вариантов только приветствуется.
На данном этапе правила диалектической дискуссии имеют чисто теоретический характер, и потому следующий шаг — их испытание на практике и доведение до действительно рабочего вида. После этого можно будет переходить к обобщению методологии на смежные проблемы — например, принятие решений в коллективе.
Реальность давно вбила нам всем в голову представление о том, что «Парламент — не место для дискуссий», причем даже не в России (которой до таких проблем еще дорасти надо), а в любом обществе, называющем себя демократическим. «Демократические» решения в нашем мире подразумевают лишь, что они минимально удовлетворяют интересам 50%+1 избирателя, как они сами эти интересы понимают; а те, кто оказался в меньшинстве, вообще не учитываются. Это неизбежно приводит к расколам коллективов и кризисам поляризации в обществе, а также полной невозможности долгосрочного планирования, потому что в любой момент к власти может прийти новая группировка, которая отменит все решения предыдущей и пойдет в противоположную сторону. Есть еще, конечно, модель консенсусной демократии, которая иногда работает в малых коллективах, но без нормальной методологии собственно достижения консенсуса о ее масштабировании можно даже не заикаться. Мой тезис в том, что выход из этого тупика есть — для этого надо адаптировать введенную в этой статье методологию диалектической дискуссии в методологию принятия решений, которая бы включала в себя в снятом виде как мажоритарно-демократическую, так и консенсусную модели. Но эту работу я оставлю на будущее — либо самому себе, либо кому-то, кто пожелает ей заняться.
И да, я знаю, что в этом тексте много упрощений, опущенных деталей и скрытых подмен тезисов. Если подробно расписывать все оговорки к каждому утверждению, то статья вышла бы не на 6 тысяч слов, а на 60. Где-то на середине я уже даже сноски писать устал. Но вот те, которые все-таки написал:
-
В реальности все немного сложнее, т.к. цвета образуют не линейное пространство, а группу симметрии SU(3). Но в интервале [0;1] она ведет себя так же, как и линейное пространство, а именно в этом интервале мы обычно работаем с цветами. Надо только с вычитанием быть аккуратнее. ↩
-
Тут я намеренно опускаю довольно важное различие между сжатием без потерь (lossless) и сжатием с потерями (lossy). Большинство моделей эмбеддингов вообще не предполагают восстановление исходного объекта по самому эмбеддингу, т.е. если и реализуют сжатие, то с большими потерями. Но это уточнение становится излишним при переходе к обсуждению человеческой памяти, в котором эти два вида сохранения информации отличаются скорее количественно, чем качественно. ↩
-
Можно еще вспомнить историю со сверточными нейронными сетями (CNN), которые повторяют структуру зрительной коры млекопитающих. Но в этом случае люди явным образом «подглядели» архитектуру у природы, что куда менее интересно, чем независимое (конвергентное) возникновение одной и той же архитектуры в природе и технике. ↩
-
Тут меня можно уличить в подмене тезиса: в начале речь шла об экономии мышления, а в конце — об экономии памяти. Но это вещи достаточно связанные. После того, как создана экономная (сжатая) модель, проводить операции с ней тоже становится экономичнее. ↩
-
Немного иначе объяснение понимается в контексте образования: там оно заключается в сведении еще неизвестных ученику сущностей к уже известным. ↩